python知识归纳¶
—— 知识记录不分先后
序列可迭代的原因:iter函数¶
python解释器需要迭代对象时,会自动调用 iter(x)
- 内置的iter函数有以下作用:
- 检查对象是否实现了 __iter__ 方法,如果实现了就调用它,获取到一个迭代器
- 如果对象中没有实现 __iter__ 方法,但是实现了 __getitem__ 方法,Python会创建一个迭代器,并尝试按顺序(索引从0开始)获取元素
- 如果上述都失败了,通常会返回该对象不可迭代的错误提示
言归正传,之所以序列可迭代的原因,正是由于它们都实现了 __getitem__ 方法。事实上,标准的序列也都实现了 __iter__ 方法。 因此如果我们自己实现一个序列对象的话也应该这么做(即在对象中实现 __iter__ 方法)。
下面简单验证一下上述的内容:
首先打开python的交互终端,输入:
>>> s = str() # 实例化字符串对象
>>> print(dir(s)) # 打印对象中的方法
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', \
'__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', \
'__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize',\
'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isdecimal', 'isdigit', \
'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace',\
'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
>>> ll = list() # 实例化列表对象
>>> print(dir(ll)) # 打印对象中的方法
['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', \
'__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__',\
'__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', \
'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
>>> from array import array # 导入数组类库
>>> print(dir(array)) # 打印类的方法
['__add__', '__class__', '__contains__', '__copy__', '__deepcopy__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__',\
'__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', \
'__reduce__', '__reduce_ex__', '__repr__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'buffer_info', 'byteswap', 'count', \
'extend', 'frombytes', 'fromfile', 'fromlist', 'fromstring', 'fromunicode', 'index', 'insert', 'itemsize', 'pop', 'remove', 'reverse', 'tobytes', 'tofile', 'tolist', 'tostring', 'tounicode', 'typecode']
从上面3种不同的内置序列中,发现都实现了 __iter__ 方法和 __getitem__ 方法。所以它们都是可迭代的,其他的序列类型,有兴趣可以自己尝试一下, 下面为了验证上述中所说的是否仅实现 __getitem__ 方法也能够迭代,所以自己实现一个序列类型。
实现可迭代序列类型:
#coding-utf-8
class Bag():
def __init__(self, maxsize=10): # 指定背包的默认最大长度
self.maxsize = maxsize
self._items = list() # 实例化容器对象,这里使用list
def __len__(self): # 求背包现有物品长度
return len(self._items)
def __getitem__(self, index):
return self._items[index]
def add(self, item):
if len(self) >= self.maxsize: # add之前判断背包是否物品已满
raise Exception('Bag is full')
self._items.append(item)
def remove(self, item):
self._items.remove(item)
def clear(self): # 清除
self._items.clear()
# 测试是否可迭代
bag = Bag()
for i in range(10):
bag.add(i)
for item in bag:
print(item)
#####################################
#输出如下 (python版本--python3.6.5)
#####################################
G:\python-base>python code_test.py
0
1
2
3
4
5
6
7
8
9
这里的输出证明了,仅仅实现 __getitem__ 方法的序列对象也是可迭代对象!
Iterable、Iterator、generator的区别¶
我也时常忘记这几个概念,或是知道是怎么回事但却并不能够准确直白的阐述出来。
‘迭代’ 在python中是我们永远避免不了的东西,不管代码里是否有 for...in... 、while ... 亦或是其他显而易见的循环语句,
我们都在不可避免的使用 ‘迭代’ 这个东西。
简单举个例子:
>>> ll = list(range(4))
>>> ll
[0,1,2,3]
>>> ll.remove(2)
>>> ll
[0,1,3]
这里虽然没有使用显式的循环,不过这里的 remove 方法能够找到列表元素 2 实则是通过循环找到的这个元素并将其移除。
从概念上看这三者的区别:
注解
- 可迭代对象(Iterable):顾名思义,能够被迭代的对象,python中所有的序列(包括但不限于list、string、dict、set等)都是可迭代对象
- 迭代器(Iterator):自身可以迭代的对象容器,该对象迭代完内部的元素就不能再被迭代使用。可迭代对象之所以可迭代就是因为其背后实现了迭代器
- 生成器(generator):所有生成器都是迭代器,不过生成器更侧重于 凭空产出,迭代器侧重于从 内部拿出。如果对这两个区别不是很清楚,后面会讲到
警告
什么是迭代:
迭代 是重复反馈过程的活动,其目的通常是为了逼近所需目标或结果。每一次对过程的重复称为一次“迭代”,而每一次迭代得到的结果会作为下一次迭代的初始值。 重复执行一系列运算步骤,从前面的量依次求出后面的量的过程。此过程的每一次结果,都是由对前一次所得结果施行相同的运算步骤得到的。例如利用迭代法*求某一数学问题的解。
对计算机特定程序中 需要反复执行的子程序*(一组指令),进行一次重复,即重复执行程序中的循环,直到满足某条件为止,亦称为迭代。
本部分参考自 [百度百科–迭代]
从代码实现侧面上看,这三者又有什么区别呢?
本文档的另一节有说到为什么序列都可以迭代的原因是在内部实现了
__iter__或__getitem__方法。 但你想没想过这些方法背后的东西,这也正是可迭代对象和迭代器的区别所在。
- 首先一言以蔽之,先给出可迭代对象和迭代器代码实现上的差别所在(迭代器和生成器之后再说):
可迭代对象是由于内部实现了
__iter__或__getitem__方法,并且如果自己实现一个迭代器,更倾向于去实现__iter__方法。其实,可迭代对象中的
__iter__方法内部实现了迭代器的实例,说直白点就是每调用一次这个函数方法都会生成一个迭代器可供我们迭代使用, 因为上面说过,迭代器使用一次(这里的一次是指完整的整个迭代过程,或者是已经迭代过几次的)后就不能再迭代出前面已经迭代出的元素了,所以, 每次想重新迭代,都会重新生成一个迭代器。>>> list_test = [1,2,3] >>> for item in list_test: # 生成迭代器 ... print(item) ... 1 2 3 >>> for i in list_test: # 生成迭代器 ... print(i) ... 1 2 3 >>>虽然这两次循环,输出的元素都是list_test中的元素,但是两次for语句执行时都生成了迭代器,并且执行完迭代之后迭代器就被弃用了。
迭代器是由于内部实现了
__iter__和__next__方法。为此我做一个简单的测试>>> a = iter(list_test) # python内置的iter()方法可生成迭代器 >>> a <list_iterator object at 0x0000027A7567FBA8> # a是一个迭代器 >>> s = str(dir(a)) # 将a中的方法转换为string并给s >>> s "['__class__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__length_hint__', '__lt__', '__ne__', '__new__', '__next__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__setstate__', '__sizeof__', '__str__', '__subclasshook__']" >>> if '__iter__' in s and '__next__' in s: # 查看是否在里面 ... print('this is Iterator') ... else: ... print('this is not Iterator') ... this is Iterator >>>你也可以用和上面同样的方法去测试可迭代对象,python中的range()方法生成的都是可迭代对象。 需要注意的是: 迭代器中实现的__iter__方法是指向自己而不是像可迭代对象中的那样去生成一个迭代器实例,原因是迭代器本身就是迭代器,所以指向自己有问题吗?
- 为什么用迭代器使用一次就不能够再次迭代了
- ———— 注意这里的 一次 是指整个迭代过程
- 先看例子:
>>> ll = [0,1,2,3,4] >>> ll [0, 1, 2, 3, 4] >>> ll_iter = iter(ll) >>> ll_iter # ll_iter是一个迭代器 <list_iterator object at 0x0000027A7567FE10> >>> next(ll_iter) # 可以使用python内置的next()方法,这里的next()方法会去调用迭代器内部的 __next__方法 0 >>> next(ll_iter) 1 >>> next(ll_iter) 2 >>> next(ll_iter) 3 >>> next(ll_iter) 4
此时将 ll 对象中的所有元素都打印出来了,如果继续调用 next(ll_iter) 会发生什么,请看:
>>> next(ll_iter)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
此时如果再调用,将会抛出 StopIteration 异常,并且之后无论调用多少次 next(ll_iter) 都会抛出这个异常,
这是提示此迭代器中已经没有元素了。既然没有元素了当然不能再使用啦,记住一点:迭代器的原则就是从里面拿出来的元素不能再拿回去了,不走回头路,除非你再创建一个新的。
注解
既然``for`` 语句执行可迭代对象会生成迭代器,那么为什么没有抛出 StopIteration 异常呢?
原因是因为在 for 语句中已经对 StopIteration 异常进行了异常处理,所以我们在终端并不会看到这个异常。
那如果不想使用 for 语句进行迭代的同时也不想看到 StopIteration 异常要如何实现呢?
其实做一个异常捕获就可以了,看下面:
>>> s = '123'
>>> s_iter = iter(s) # 创建一个迭代器
>>> s_iter
<str_iterator object at 0x0000027A7567FF28>
>>> while 1:
... try:
... print(next(s_iter))
... except StopIteration: # 捕获异常
... del s_iter # 废弃该迭代器
... print('Iterator was deled') # 输出异常捕获后的提示
... break # 退出循环
...
1
2
3
Iterator was deled
上述结果能看出,利用 while 循环遍历了迭代器并捕获了异常。这些步骤在 for 语句中都已经帮我们完成了。
实现自己的可迭代对象
前面说了,要实现可迭代对象就必须要在对象内的
__iter__方法中返回迭代器的实例。借用一下前面已经实现的bag的可迭代类型:
#coding-utf-8 class Bag(): def __init__(self, maxsize=10): # 指定背包的默认最大长度 self.maxsize = maxsize self._items = list() # 实例化容器对象,这里使用list def __len__(self): # 求背包现有物品长度 return len(self._items) def __getitem__(self, index): return self._items[index] def add(self, item): if len(self) >= self.maxsize: # add之前判断背包是否物品已满 raise Exception('Bag is full') self._items.append(item) def remove(self, item): self._items.remove(item) def __iter__(self): for item in self._items: yield item def clear(self): # 清除 self._items.clear()上述就是实现了一个可迭代的对象,我们重点关注
__iter__和__getitem__方法。这里在__iter__中用到了一个关键字yield,这个关键字是构建生成器函数的关键字。可以说只要有yield存在的函数就是生成器表达式。注解
关于
yield的解释:
yield是python的关键字,它具有和return类似的功能,但它却又和return具有很大的差别。 它们的共同点都是可以返回元素,不同点是return返回后便不会再执行该函数。而yield返回值后,该函数会在返回值的yield(如何函数中有多个yield时)处将函数暂停。继续执行函数, 会从上次暂停的yield处继续向下执行直到遇到下一个yield时再返回它对应的值。比如你看下面这个代码:>>> def test(): ... yield 1 ... yield 2 ... yield 3 ... >>> s = test() >>> s # s是一个生成器对象 <generator object test at 0x0000027A754DD1A8> >>> next(s) 1 >>> next(s) 2 >>> next(s) 3 >>> next(s) Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration先创建一个含有
yield的函数,此时s就是一个生成器对象,之前说过所有生成器都是迭代器,所以用next()函数打印出函数中的元素,我们就可以发现这里的1、2、3都是逐次打出直到出现StopIteration, 这也印证了两点:
- 生成器就是迭代器 (反之看如何看待,如果细分概念的话可以说迭代器不一定生成器)
yield是生成器关键字,它具有 暂停返回 的功能- 任何含有
yield的函数都可称为生成器函数 (即产生生成器对象的工厂)至此,我们上面自己实现的可迭代对象中的
__iter__方法中的内容就可以理解了吧。它返回的就是一个迭代器(生成器)实例。其实上面实现
__iter__方法中的内容也可以更改为: 利用自己实现的一个迭代器类型,在__iter__方法中调用这个迭代器类型产生迭代器实例。
实现自己的迭代器实例
实现迭代器实例前面讲过是要在内部实现
__iter__和__next__方法。并且__iter__方法要返回自身。所以自己实现的话可以这样写:class MyIterator: def __init__(self, items): self.items = items self.index = 0 def __next__(self): try: item = self.items[self.index] except IndexError: raise StopIteration() self.index += 1 return item def __iter__(self): # 在迭代器类型中这里要返回自身 return self不过python生而就是为了简洁优雅,所以这种写法只做理解,实际中还是直接用
yield来的更清爽简洁不是吗?
注解
什么是生成器表达式?
这是除了生成器函数,还有一个叫做生成器表达式的概念,我们都知道列表推导式,看下面:
>>> def test():
... yield 1
... yield 2
... yield 3
...
>>> list_1 = [i for i in test()] # 列表推导式
>>> list_1 # 列表推导式能够将内部要迭代的变量一次全拿出来
[1, 2, 3]
>>> generator_1 = (item for item in test()) # 生成器表达式,和列表推导式的区别是外面用的括号
>>> generator_1
<generator object <genexpr> at 0x0000027A754DD308>
>>> next(generator_1)
1
>>> next(generator_1)
2
>>> next(generator_1)
3
>>> next(generator_1)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
生成器表达式可以将某些比较简单的生成器函数用一句话表示出来,并且不需要加入 yield,你看上面那个是不是就没有关键字 yield。其实这样好也不好,好处是看着简洁,不好的地方是其他人不一定知道那是一个生成器。
什么是协程?¶
——含有yield的函数不一定是生成器函数,它也可能是协程
注解
字典为动词 to yield 给出了两个释义:产出 和 让步
对于python生成器中的yield来说,这两个含义都成立。yield item 这行代码会产出一个值提供给 next() 的调用方,同时还会做出让步,暂停执行生成器并把执行权利交给调用方,直到调用方需要另一个值时再使用next() 函数。调用方会从生成器中拉取值。
协程与生成器类似,不过协程中,yield 通常出现在表达式的右边(例如:x = yield),可以产出值(产出 yield 后表达式的值),也可以不产出值(即 yield 后面没有表达式,此时产出 None)。
此外,调用方还可以通过使用 .send(item) 方法将数据 item 传给协程使用。甚至 yield 可以不接收或传出任何数据。
协程作为一种流程控制工具,使用它可以实现协作式多任务:协程可以把控制器让步给中心调度程序,从而激活其他协程。从根本上将 yield 视作 控制流程的方式 就好理解协程了。
生成器如何进化成协程¶
由于
yield可以在表达式中使用,并且生成器中提供了API如:
.send(value)、.throw()、.close()方法- 生成器的调用方可以使用
.send(value)发送数据value- 调用方可以使用
.throw()方法抛出异常并在生成器中处理.close()方法是终止生成器,除了异常的因此,生成器可以作为协程使用协程是指一个 过程,这个过程与调用方 协作,产出由调用方提供的值。
用作协程的生成器¶
>>> def my_coroutine(): # 协程使用生成函数定义:定义体中有yield表达式 ... print('start -->') ... x = yield # yield在等式右边,此时yield后面没有表达式,此时是没有产出,或者说产出为None ... print('second -->',x) # 输出由调用方send来的x的值 ... y = yield ... print('last -->', y) ... >>> my_cor = my_coroutine() # 创建一个生成器实例 >>> my_cor <generator object my_coroutine at 0x000002F7FA08D258> >>> next(my_cor) # 预激 协程,使其运行到第一个yield处 start --> >>> my_cor.send(10) # 给第一个yield发送数据为10 ,此时x=10 second --> 10 # 输出x的值。说明send正确,此时到了第二个yield处 >>> my_cor.send(20) # 给第二个yield发送数据为20 last --> 20 # 此时输出y的值,输出后生成器函数继续执行,发现已到函数末尾。跳出异常 #Traceback (most recent call last): #File "<stdin>", line 1, in <module> #StopIteration >>>
- 协程在整个过程中可以处于4个状态当中的某一个,状态查询是利用
inspect库的getgeneratorstate()方法获取。分别有以下4中状态:
GEN_CREATER: 等待开始执行GEN_RUNNING: 解释器正在执行GEN_SUSPENDED: 在yield表达式处暂停GEN_CLOSED: 执行结束警告
因为
send方法的参数会成为暂停的yield表达式的值,所以仅当协程处于暂停状态时才能够调用send方法。有一个特殊情况是协程还未激活的情况下(即处于GEN_CREATER), 这时,可以使用send(None)预激协程或是调用next(my_cor)激活协程。>>> def my_coroutine(a): # 建立用作协程的生成器函数,注意这个函数有参数 ... print('start --> a = ', a) ... x = yield a ... print('second --> x =', x) ... c = yield x + a ... print('last --> c = ', c) ... >>> my_cor = my_coroutine(1) # 传递参数1并创建生成器实例 >>> my_cor # 这是一个生成器 <generator object my_coroutine at 0x000002F7FA08D1A8> >>> from inspect import getgeneratorstate >>> getgeneratorstate(my_cor) # 查询此时生成器状态 'GEN_CREATED' # 等待开始执行 >>> my_cor.send(None) # 利用send(None) 预激生成器,这里也可以使用next(my_cor) start --> a = 1 1 # 这里的1 是式子 yield a 产出的值 ,yield有产出也有让步 >>> getgeneratorstate(my_cor) # 上面产出后,暂停在第一个yield处,这时查询状态,为暂停状态 'GEN_SUSPENDED' >>> my_cor.send(10) # 此时由调用方发送数据10 给第一个yield,此时yield后面的式子的值就为10,将10赋值给x second --> x = 10 # 输出x的值 11 # 这里的11是第二个yield x + a 式子产出的值,因为x为10 a为1 >>> getgeneratorstate(my_cor) # 上面产出后,暂停在第二个yield处,查询状态为暂停状态 'GEN_SUSPENDED' >>> my_cor.send(20) # 发送数据给第二个yield,此时 第二个yield后面的式子的值为20,即c为20 last --> c = 20 # 输出c为20,由于函数进行到尾部了,所以下面就返回异常 #Traceback (most recent call last): #File "<stdin>", line 1, in <module> #StopIteration >>>上面的执行过程中特别需要注意的是:
警告
- 对于
x = yield a和c = yield x + a这两句来说,其实可以将其看作是有yield分开的两个部分。
- 第一部分:
yield先产出结果给调用方,然后暂停生成器函数,控制权交给调用方,调用方可以做一系列处理,直到调用方调用.send()方法传递数据- 第二部分:生成器接收到来自
.send()的数据后,yield后面的表达式不管是什么样子,它们的值统一为.send()方法传递进来的值- 当利用
.send()方法传递值这句话执行时,控制权才再度交回给生成器,这时才将传递进来的值赋值给等式左边的变量
yield在这其中起着至关重要的作用。图示如下:
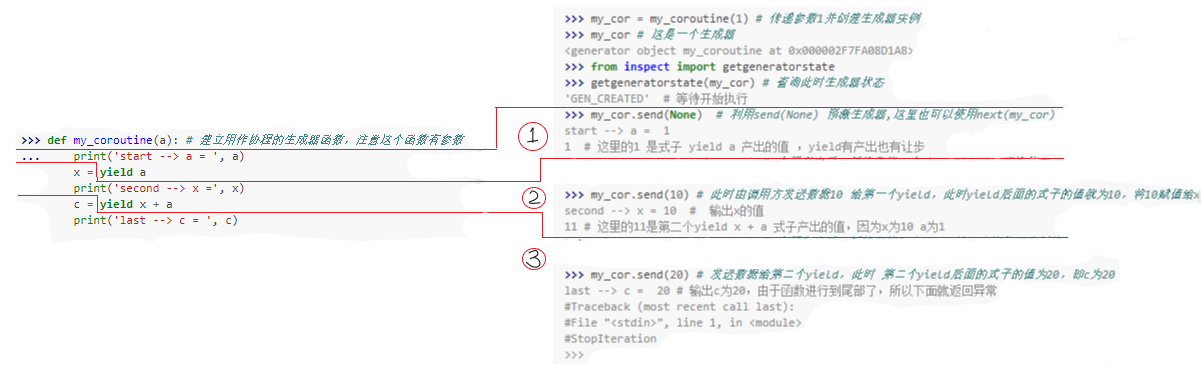
看清楚每一步的走向,都是在
yield处暂停。